[yum update]した際、サーバが起動できなくなった時の対処法

| 日付 | 2020-11-22T16:59:00 |
| 分類 | WEBマスター |
| 画像 | 2枚 |
| 訪問数 |
こんばんは。2020年11月21日、AWS EC2のCentOS7.9でyum update -yしてからサーバがフリーズして停止すらできないことが起きたので、対処法を記します。大雑把に説明すると、カーネルが破損したそうなので、一旦EBSを別インスタンスにアタッチ、マウントしてルートディレクトリにして、破損したカーネルを、GRUBブートローダーでデフォルトのカーネルを更新するして元に戻していくという作業になります。
バージョンの確認
CentOS Linux release 7.9.2009 (Core)
~~~(省略)
Error: systemtap-client conflicts with systemtap-runtime-4.0-10.el7_7.x86_64
Error: systemtap-devel conflicts with systemtap-runtime-4.0-10.el7_7.x86_64
You could try using --skip-broken to work around the problem
** Found 131 pre-existing rpmdb problem(s), 'yum check' output follows:
このようなエラーが表示される中でyでアップデートを実行してしまうと、途中からフリーズして動かなくなります。停止させても1時間ほど停止中となり、強制的に停止させたりEBSを強制デタッチすることによって停止済みにできました。
デタッチに成功したら新しいインスタンスを生成します。 OSとアベイラリティゾーンを必ず同じにしましょう。CPUなどは無料枠で良いでしょう。新しいインスタンスを起動したら一旦yum update -yをしておきます。新しく作ったばかりのインスタンスなら、このアップデートではエラーになることはありません。
アップデートが無事終わったら一旦インスタンスを停止します。
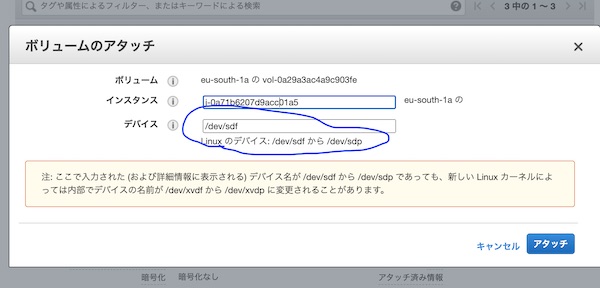
停止後、元のインスタンスボリュームをデタッチします。このとき、元のインスタンスのEBSのルートボリュームを控えておいてください。/dev/sda1や/dev/sdfなどの場合があり、救出後、再度アタッチするときに同じルートボリュームを設定しないと起動できなくなります。デフォルトでは前回と同じsda1になっていません。忘れるとかなり面倒になります。

メモしたら、新しい救出用インスタンスにアタッチします。この時はsdbかsdfという名前になり、起動後にls -al /dev/xv*でxvdbかxvdaにという名前で表示されているのを確認。sdbならxvdb、sdaならxvdaという風にsがxvに変わってややこしいです。
brw-rw----. 1 root disk 202, 0 Nov 15 11:21 /dev/xvda
brw-rw----. 1 root disk 202, 1 Nov 15 11:21 /dev/xvda1
brw-rw----. 1 root disk 202, 0 Nov 21 13:41 /dev/xvdf
brw-rw----. 1 root disk 202, 1 Nov 21 13:41 /dev/xvdf1
mount /dev/xvdf1 /ebs
lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
xvda 202:0 0 8G 0 disk
└─xvda1 202:1 0 8G 0 part /
xvdf 202:0 0 500G 0 disk
└─xvdf1 202:1 0 500G 0 part /ebs # ←元々のサーバのHDDがマウントされたことを確認
ls /ebs
bin boot dev etc ezdata home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
これで元々のEBSを緊急用インスタンスにマウントでき、いじれるようになりました。次にルートディレクトリなども反映させます。
mount -o bind /run /ebs/run
mount -o bind /proc /ebs/proc
mount -o bind /sys /ebs/sys
chroot /ebs
カーネル破損して生じたバグの根元であるGRand Unified Bootloaderを修正
GRUB_TIMEOUT=1
GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g' /etc/system-release)"
GRUB_DEFAULT=0
GRUB_DISABLE_SUBMENU=true
GRUB_TERMINAL="serial console"
GRUB_SERIAL_COMMAND="serial --speed=115200"
GRUB_CMDLINE_LINUX="console=tty0 crashkernel=auto console=ttyS0,115200"
GRUB_DISABLE_RECOVERY="true"
3行目のGRUB_DEFAULT=0の0をsavedに変える
GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g' /etc/system-release)"
GRUB_DEFAULT=saved
GRUB_DISABLE_SUBMENU=true
GRUB_TERMINAL="serial console"
GRUB_SERIAL_COMMAND="serial --speed=115200"
GRUB_CMDLINE_LINUX="console=tty0 crashkernel=auto console=ttyS0,115200"
GRUB_DISABLE_RECOVERY="true"
grubを更新して、/boot/grub2/grub.cfgファイルを再生成します。
次回の再起動時に安定したカーネルが読み込まれるように設定
exitでrootを抜け、/ebsを全てアンマウント
umount /ebs/run
umount /ebs/proc
umount /ebs/sys
umount /dev/xvdf1
ターミナルを終了、新しく作ったインスタンスを停止、EBSをデタッチ、元々のインスタンスにアタッチ、無事起動できれば完了。
参照元: How do I revert to a known stable kernel after an update prevents my Amazon EC2 instance from rebooting successfully?
| 日付 | 2020-11-22T16:59:00 |
| 分類 | WEBマスター |
| 画像 | 2枚 |
| 訪問数 |
Thank you for watching until the end